
Мовні моделі: Bing, Claude, Bard, Chat GPT-4. Ми зробили порівняння
Ми вирішили порівняти чотири популярні мовні моделі штучного інтелекту, з якими працює більшість фахівців у цій сфері. Одразу можемо сказати, що кожна з цих моделей має свої сильні сторони в певних напрямах. Ми не радимо відкидати жодну з них. Але давайте розглянемо все по порядку.
Отже, які мовні моделі ми тестували?
- Claude - віртуальний помічник від Anthropic, створений у 2022 році. Навчений вести природну бесіду та відповідати на запитання користувачів.
- Bard - чат-бот на основі нейромережі від Google, представлений у лютому 2023 року. Призначений для пошуку інформації та діалогу.
- Bing - пошукова система від Microsoft, запущена у 2009 році. Нова версія з ШІ вийшла у 2023 році. Використовує ШІ та машинне навчання для покращення результатів.
- ChatGPT-4 - четверта версія чат-бота від OpenAI, представлена у 2023 році. Вміє вести діалог, генерувати текст та відповідати.
Ми оцінювали кожне завдання за 5-бальною шкалою, де 0 – зовсім не впорався, а 5 – чудово впорався.
Завдання 1
Потрібно було зробити рерайт тексту обсягом близько 1000 знаків. Текст завантажувався безпосередньо у сервіс.
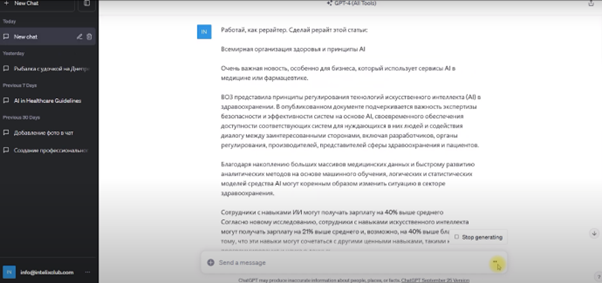
Bard написав гарний структурований текст зі вступом, тезами та висновком. Єдине - текст вийшов на 500 знаків більше, що не завжди добре для рерайту. Ставимо 4 бали.
Спочатку Claude дав текст англійською, але після уточнення зробив якісний рерайт українською з дотриманням обсягу. Заслужив 5 балів.
Bing зробив невеликий рерайт, скоріше спрацював як фактчекер, дав кілька посилань. Виконав завдання, але не зовсім так, як просили. Ставимо 3 бали.
ChatGPT-4 відмінно впорався, додав образності і зробив текст семантично багатшим. Заробив 5 балів.
Завдання 2
Потрібно було написати продаючий текст на основі сторінки інтернет-магазину зі звичайними навушниками.

Claude не мав виходу в інтернет, але написав гарний продажний текст саме про цей товар. Отримує 5 балів.
Bard відповів, що не може тут допомогти. 0 балів.
ChatGPT-4 знайшов потрібну інформацію та написав непоганий продажний текст. 5 балів.
Bing зібрав багато інформації, але його текст вийшов дуже стандартно. 4 бали.
Завдання 3
Потрібно було прочитати й опиcати документ у PDF-форматі. Це була комерційна пропозиція.
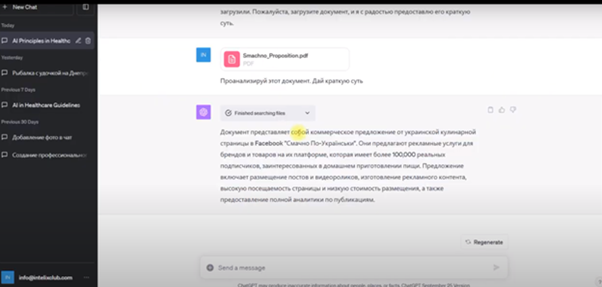
Claude справився на «п'ять». Документ завантажився, був прочитаний, видана добре структурована інформація про його суть.
ChatGPT-4 також зміг прочитати документ, єдина відмінність від Клода, він дав опис документа в описовій формі, тоді як Клод зробив це тезово в стовпчик. ChatGPT-4 теж отримує п'ятірку.
Bard і Bing не побачили та не змогли прочитати документ. 0 балів.
Завдання 4
Слід було проаналізувати випадкове фото популярної іграшки та описати зображення.
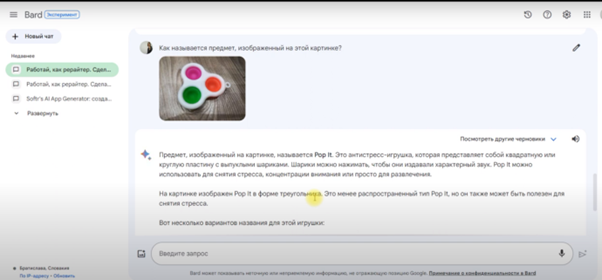
Bing відразу назвав іграшку, дав опис та посилання. 5 балів.
Claude, ChatGPT-4 і Bard теж добре впоралися з описом. Але посилань не дали. Проте, цього в завданні і не було, будемо об'єктивні. Всі отримують по 5 балів.
Завдання 5
Потрібно було зробити синопсис сценарію серіалу обсягом 33 сторінки. Це перевірка на можливості "з'їсти великий об'єм тексту.
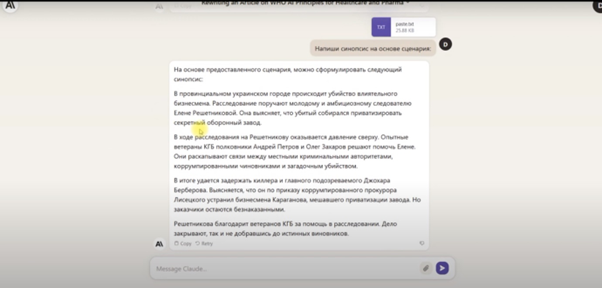
Bing і Bard завантажили лише 5 сторінок, тому їхні синопсиси вийшли неповними. По 3 бали.
ChatGPT-4 не зміг виконати завдання, про що чесно нас повідомив. 0 балів.
Лише Claude справився ідеально, зробив повний синопсис. 5 балів.
Завдання 6
Слід було написати статтю для блогу про риболовлю. Для цього нашим нейронкам ми дали повній промпт, схожий на ТЗ для копірайтера.
Bard створив скоріше гарний план-конструктор статті, ніж статтю. 4 бали.
Статті Claude та Bing вийшли дещо сухими, я б таке не читав. По 3 бали.
ChatGPT-4 написав чудову статтю, готову для публікації. Написав літературною мовою, додав порівняння і "особисту" думку - 5 балів.
Завдання 7
Потрібно було написати сценарій ролика для TikTok на основі сценарію конкурента. Для цього ми використали професійний промпт.
Наші нейронки мали завдання написати ці сценарії у таблиці. Додати текст ведучого, побудувати кадр і порахувати хронометраж.
Claude чудово справився з текстом та описом дії. 5 балів.
ChatGPT-4 теж відмінно впорався зі всіма параметрами - 5 балів.
Bard і Bing мали проблеми з текстом, але справилися з ракурсами та хронометражем. По 4 бали.
Завдання 8
В останньому завданні потрібно було згенерувати картинки парку та чашки кави.
Bing і Claude не вміють малювати. 0 балів.
ChatGPT-4 впорався з завданням.

Bard також створив цікаві зображення. По 5 балів кожному, маю на увазі Bard і ChatGPT-4

Отже, підсумовуючи, ChatGPT-4 найкраще впорався із більшістю завдань. За ним йде Claude, потім Bing і останнім Bard.
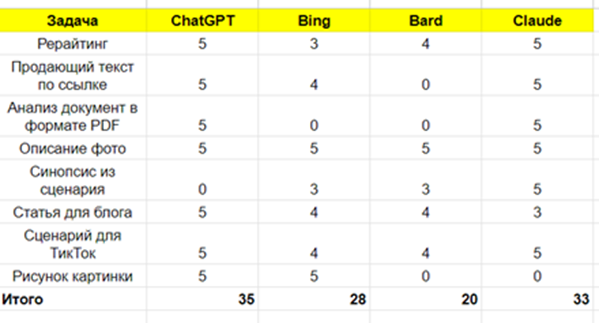
Це говорить швидше про їхню універсальність, а не про якість. Усі моделі дуже якісні і дуже потужні. Тож використовуйте ту, що найбільше підходить саме для ваших задач.
А більше про штучний інетелект і нейромережі читайте в нашому телеграм каналі.