

Generative AI development has become a huge part of the IT world for the last couple of years, especially its significant part - Large Language Model engineering. We have heard a lot about such LLMs as OpenAI GPT-4, Google Bard, LLaMA, OPT, T5, Bloom, Cohere, Palm, and many others.
According to Yahoo Large Language Model (LLM), the Market Size is going to grow by 40.8 Billion USD by 2029 at a CAGR of 21.4% These numbers are impressive and they show that within the next 5 years, the LLM industry will grow and that’s why more and more companies can get valuable benefits from different kinds of LLMs.
Open Source LLMs
Let’s start with the best open-source large language models and talk about them. Perhaps, you have seen the well-known Evolutionary Tree of large language models.
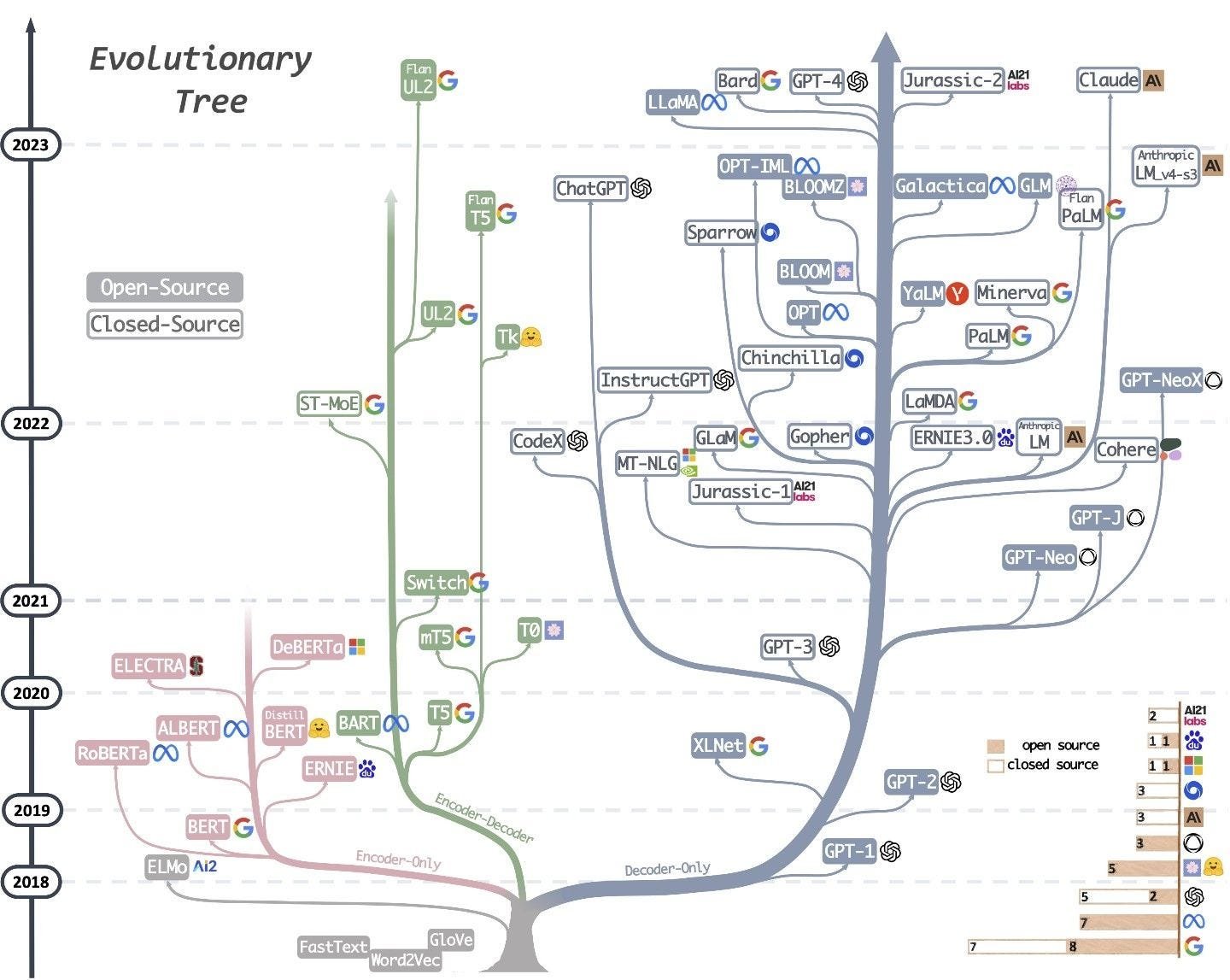
Open source LLMs take the bigger part of the tree and there are many reasons for this. As far as we can see, the most progressive open-source LLMs are LLaMa, OTP-IML, GLM, UL2, TP, and Galactica. Let’s dive deeper into some of them.
LLaMA
LLaMA or Large Language Model Meta AI is one of the most popular open-source LLMs that was released by Meta in February 2023. There are two well-known versions of this model for now: LLaMA 1 and LLaMA 2.
As far as LLaMA 1 was only available through a non-commercial license and limited to 100,000 requests for access, Meta AI has recently released LLaMA 2 - a significantly improved version that has already become a big competitor to GPT-3.5 and other closed-sourced LLMs.
It is worth saying that Meta also developed the type of LLaMA 2 specifically for AI chatbot application development, called LLaMA-2-chat. Having been trained on more than 1 million parameters, LLaMA-2-chat is one of the best-performing open-source models made for chatbots.
Another important aspect of LLaMA is AI security and safety. Meta focused a lot on this point and they tried to filter out as much personal data from their datasets as they could, helping LLaMA conform to ethical guidelines on a high level. As a result, LLaMa 2 consistently achieves violation scores below 10%, which is much lower than other LLMs at the moment.

To sum up, LLaMA 2 is a modern model proficient at various natural language processing (NLP) tasks and functions, such as AI content generation, personalized recommendations, and AI customer service automation.
Wizard Language Model
WizardLM is one of the most powerful conversational language models with seven billion parameters. Its training process uses a new method called Evol-Instruct and is able to generate approximately 70,000 instructions (OpenCompass). WizardLM models were released by engineers from Microsoft and Peking University in May 2023, and it opened absolutely new way of LLM training.
WizarLMs are based on LLaMA 1, and similar to Vicuna LLM but with the main advantage based on the Evol-Instruct method that makes instructions of higher quality than manually generated instructions. Moreover, It also helps automate the instruction generation process on a massive scale. That is actually one of the best advantages of all open source large language models.
Comparing WizardLM and GPT-4 as the difference between open source and closed source LLMs, we may see on the graph below how they perform unique tasks in a wide range of fields.

So, obviously, WizardLM models are capable of handling various demanding tasks in AI content generation, such as academic writing, answering difficult questions, and translating texts into multiple languages.
Vicuna
Vicuna is an open-source large language model that is trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT (Lmsys). Vicuna was released in March 2023 and developed by a team from various institutions, including UC Berkeley, CMU, Stanford, and UC San Diego.
There are 2 main models available for now: the Vicuna-13B and Vicuna-33B. One of the most exciting things about Vicuna LLM is the low training budget. It is only $300. Moreover, Vicuna has the ability to achieve comparable performance to various other LLMs like LLaMA 1 and ChatGPT.
Preliminary evaluation using GPT-4 as a judge shows Vicuna-13B achieves more than 90% quality of OpenAI ChatGPT and Google Bard while outperforming other models like LLaMA and Stanford Alpaca in more than 90% of cases. Let’s see what it looks like on the chart below.
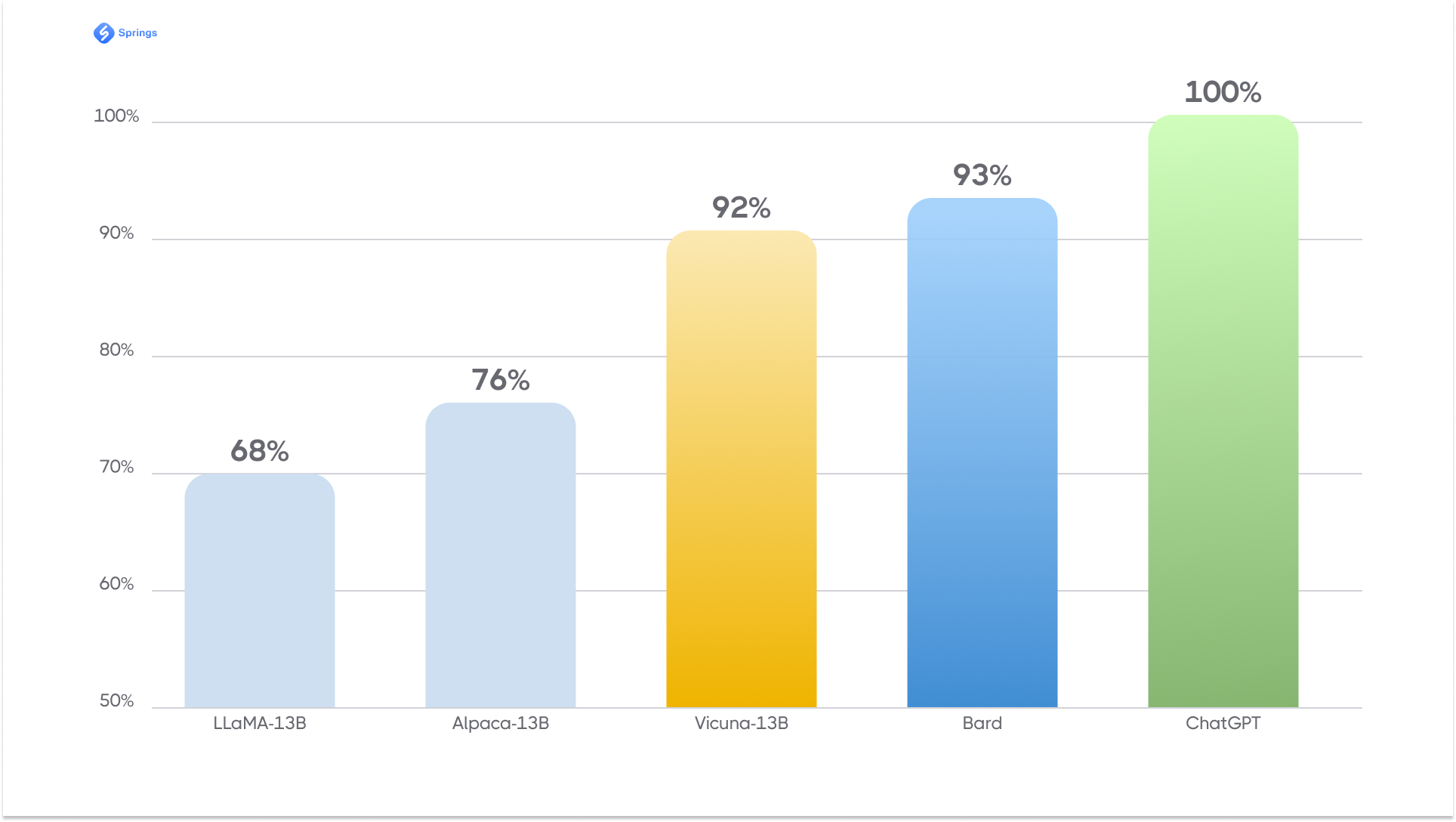
A nice point is that Vicuna has a free online demo that you may use for testing before making any decisions about using it. Unfortunately, Vicuna has certain limitations. For example, Vicuna is not good at tasks involving reasoning or mathematics, and it may have limitations in accurately identifying itself or ensuring the factual accuracy of its outputs. Additionally, it has not been sufficiently optimized to guarantee safety or mitigate potential toxicity or bias.
Closed Source LLMs
We have already got some views on open source LLMs, so let’s compare them to closed source LLMs. Closed-source LLMs are obviously more popular than open source. The most famous examples of closed source large language models are OpenAI GPT-4, Google Bard, Claude, Cohere, and Jurassic. Let’s examine in detail some of these LLMs.
ChatGPT
OpenAI’s GPT is definitely the most popular LLM nowadays. Millions of people use ChatGPT almost every day. There are multiple projects that can be built using GPT integration so let’s see how it works.
GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) developed in Python and other technologies, exhibiting human-level performance on various professional and academic benchmarks (OpenAI). Unfortunately, OpenAI did not release the technical details of GPT-4, so the technical report explicitly refrained from specifying the model size, architecture, or hardware used during either training.
While the report described that the model was trained using a combination of first supervised learning on large data, then reinforcement learning using both human and AI feedback, it did not provide details of the training, including the process by which the training dataset was constructed. The report claimed that "the competitive landscape and the safety implications of large-scale models" were factors that influenced this decision. The ex-CEO of OpenAI Sam Altman stated that the cost of training GPT-4 was more than $100 million.
There are two main versions that are mostly used in ChatGPT integration nowadays: GPT-3.5 and GPT-4. OpenAI stated that GPT-4 is "more reliable, creative, and able to handle much more nuanced instructions than GPT-3.5. They produced two versions of GPT-4, with context windows of 8,192 and 32,768 tokens, a significant improvement over GPT-3.5 and GPT-3, which were limited to 4,096 and 2,049 tokens respectively. Let’s have a look at the Performance Testing Report provided by OpenAI.
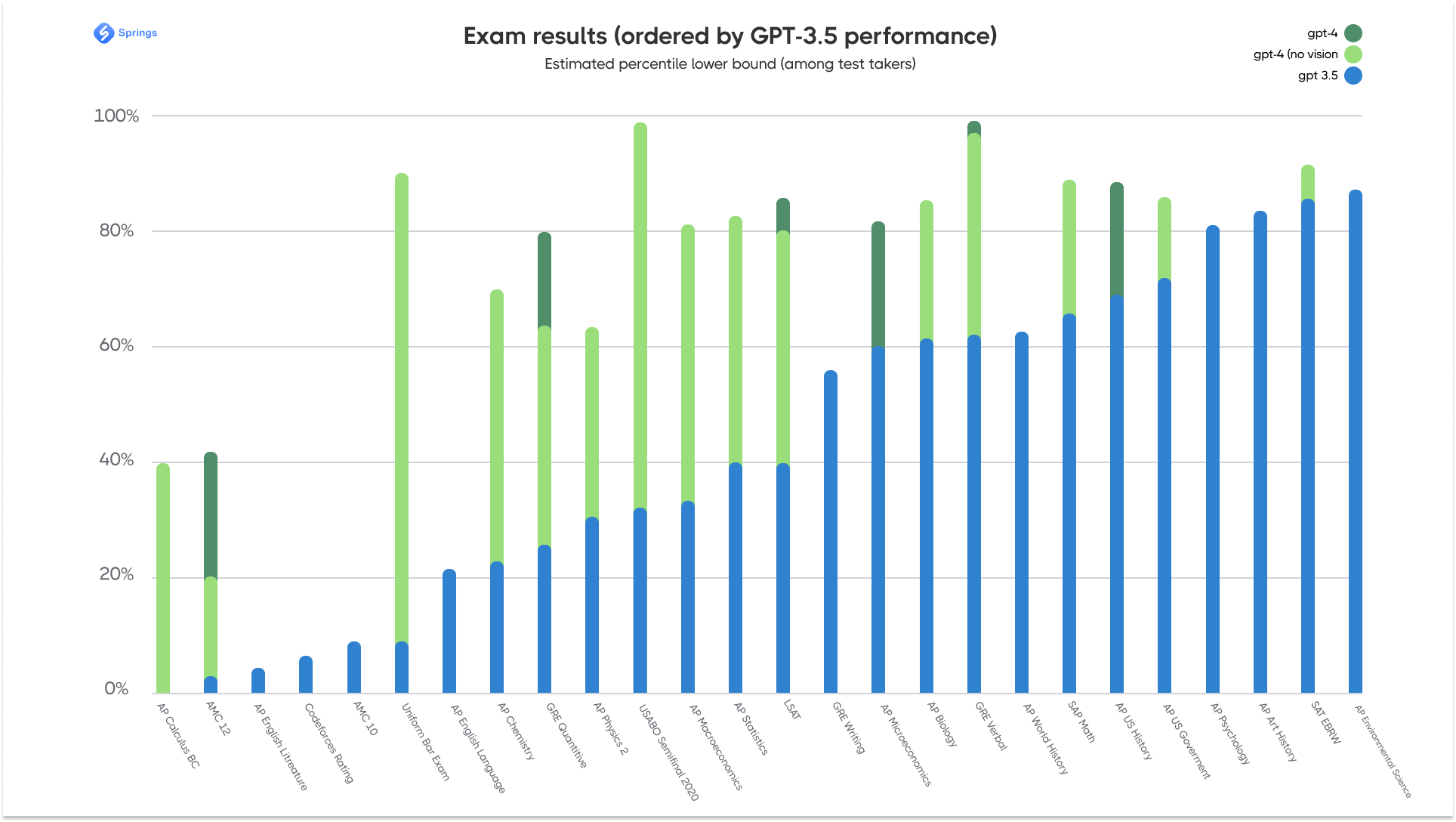
Bard
Google as one of the most powerful IT companies in the world couldn’t stay away from creating a big market player. Google Bard was developed as a direct response to the rise of OpenAI’s ChatGPT and was released in a limited capacity in March 2023 to lukewarm responses, before expanding to other countries in May.
The latest version of Bard is based on the PaLM 2 training model. Google PALM2’s training was enriched by Infiniset - a special dataset primarily focused on dialogues and conversations. Moreover, Infiniset has been feeding on Common Crawl, Wikipedia, published documents, and a rich assortment of web-based conversations.
Google Bard is based on a neural network architecture that is trained using unsupervised learning techniques. It is pre-trained on a large corpus of text data, allowing it to learn patterns and relationships in the data without being explicitly told what to do.
Another interesting point is that this model uses bidirectional encoding to understand the context of words and phrases, allowing it to generate text that is more coherent and natural sounding.
One of the strongest points of Bard is the capability of AI Image generation that OpenAI’s GPTs are missing for now. Overall, Bard is a really strong competitor to ChatGPT and even after the expected release of GPT-5, we will obviously see the new features and benefits from Google developers.
Сlaude
According to its creator Anthropic, Calude is a next-generation AI assistant based on Anthropic’s research into training helpful, honest, and harmless AI systems. Claude LLM relies on reinforcement learning from human feedback (RLHF) to train a preference model over their outputs, and preferred generations are used for later fine-tunes. RLHF trains a reinforcement learning (RL) model based on human-provided quality rankings: humans rank outputs generated from the same prompt, and the model learns these preferences so that they can be applied to other generations at a greater scale. This method Anthropic developers called Constitutional AI.
Anthropic has announced the release of Claude 2 in the summer of 2023. Claude 2 has improved performance, and longer responses, and can be accessed via API as well as a new public-facing beta website.
It is worth saying that Claude is a serious competitor to ChatGPT, with its improvements in many cases. The writing style of Claude 2 model is more verbose, but also more naturalistic. Its ability to write coherently about itself, its limitations, and its goals seems to also allow it to more naturally answer questions on other subjects. One of the biggest advantages of Claude 2 over GPT-4 is that it is more affordable - it generates safer, harmless, and legal output. The other differences between these great competitors we may see in the table below:
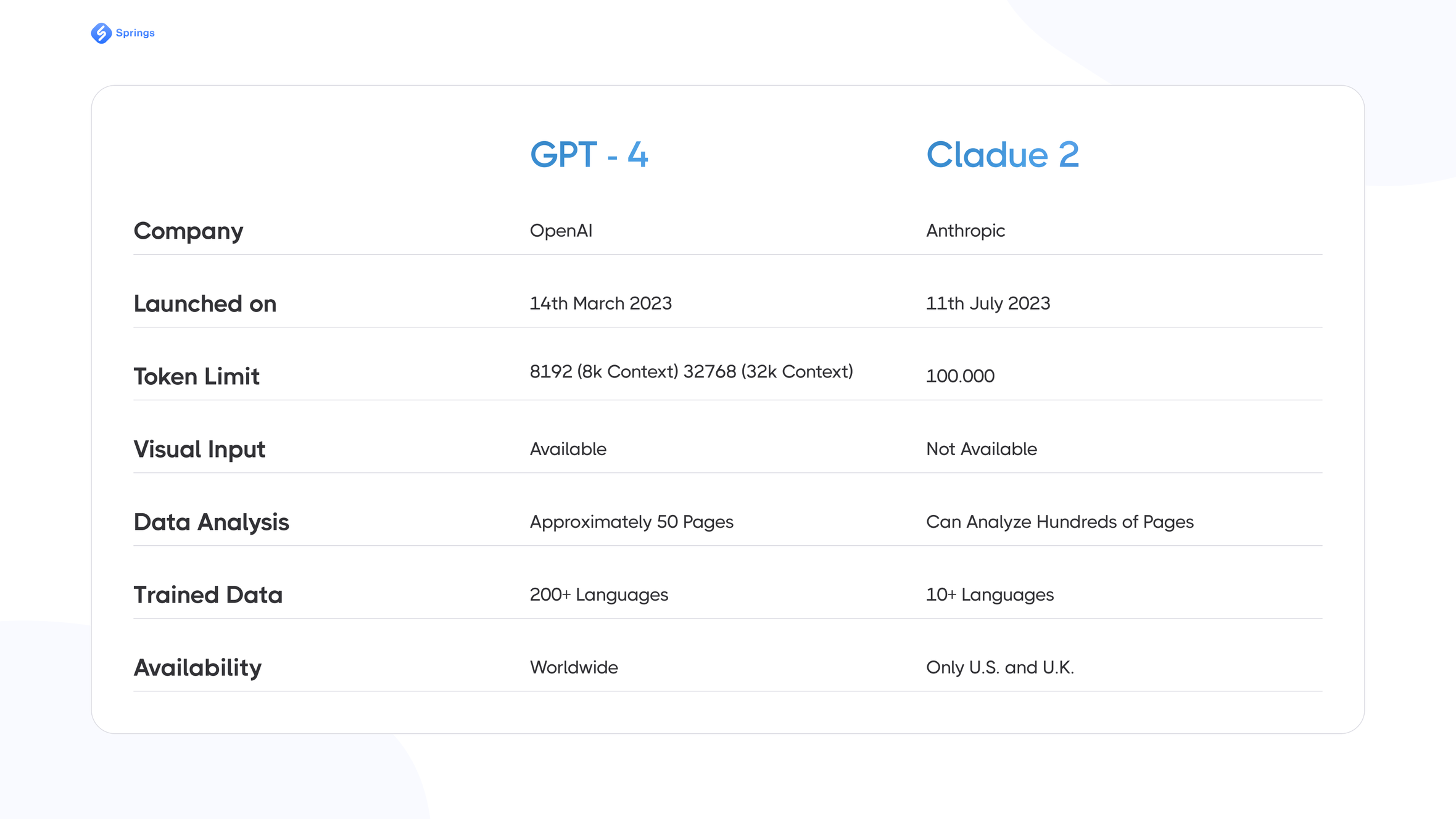
Finally, while conceived as a demonstration of "constitutional" principles, Claude is not only more inclined to refuse inappropriate requests but is also more fun than GPT-4 and ChatGPT in some way.
Pros & Cons
Both open source and closed source large language models can be used for different AI use cases, especially for AI startups. At the same time, choosing the right LLM can be not an easy decision so let’s try to define their crucial advantages and disadvantages.
Advantages of open-source LLMs
Open source LLMs are language models whose source code is publicly available and can be freely accessed, used, modified, and distributed. Their main pros are as follows:
- Free to Use. A lot of open-source language models are free of charge so you may save costs on their integration to the AI solution.
- Easy to Customize. Almost all open-source LLMs are easier to run, customize, and modify because of their underlying architecture and public availability.
- Transparency. Best open-source large language models provide full visibility into the model’s inner workings that can help in building trust relations with potential clients.
- Community Support. Open source language models are often supported by various communities of ML engineers and python developers.
- Additional Control. While using open-source models you have total control over the model’s training data and its applications.
Disadvantages of open-source LLMs
There are many examples of open-source LLMs that have cons: Alpaca1, BLOOM2, Cerebras-GPT2, Dolly2, Falcon2, FastChat2, FLAN-T52, FLAN-UL22, GPT-J2. The biggest disadvantages of such models are:
- Limited Resources. Open-source LLMs often rely on volunteers which can lead to fewer resources for development, addressing bugs, adding features, and optimizing performance.
- Security Issues. Obviously, open-source models can be vulnerable, and their communities may not always be quick to address them. So, this could become a big problem, especially in applications where data security is crucial.
- Integration Challenges. Integrating open-source LLMs into existing systems can raise such challenges as compatibility issues, lack of standardized APIs, or other related problems.
- IP Concerns. Some companies and enterprises may be hesitant to use open-source LLMs due to concerns about intellectual property (IP), especially if the model was trained on proprietary or sensitive data.
As far as we may see, the description of the pros and cons shows the significant difference between open source and closed source LLMs. So, let’s dive into closed-source models now.
Advantages of closed-source LLMs
For sure, such IT giants as OpenAI and Google are trusted by millions of users in the world, so their LLMs will definitely have many advantages, as well as other closed-source models:
- Legal Protection. Companies and startups that use closed-source models usually have clear legal agreements and terms of service that provide legal protections for their businesses.
- Scalability. Almost all closed-source LLMs are designed to scale efficiently, with the backing of the company's resources. This option makes them suitable for apps that require high levels of scalability and performance, especially in the field of Conversational AI.
- Data Security. Closed source models may come with enhanced data security features, providing assurances to businesses about the protection of sensitive user data. This could be a very important benefit for companies that want to use prompt engineering in their AI solutions.
- Regular Updates. The proprietary models are usually constantly maintained, and their developers regularly release updates to improve the model: performance, new features, bug fixes, security vulnerabilities, etc.
- High-Level Support. Most closed-source model users receive dedicated support from the company that developed the model or their communities. Such support may include assistance with integration, troubleshooting, or addressing any other issues from users.
- Comprehensive API Docs. Closed-source large language models are usually released with detailed API documentation. It really helps users to understand all the capabilities of the model, implement it more effectively, and troubleshoot issues faster.
Disadvantages of closed-source LLMs
Despite the fact that closed source LLMs have multiple benefits, they also have some drawbacks we need to consider:
- Vendor Dependency. The companies using closed-source LLMs are fully dependent on the AI/ML development company that maintains the language model. So, in case the company discontinues support or goes out of business, the model users may face real challenges in maintaining or updating their systems.
- Limited Flexibility. Almost all closed-source models are less suitable for experimentation and research purposes due to limited access to the model's internal architecture and training data. This could be an issue for their fine-tuning and further customization.
- Licensing and Costs. It is a well-known fact that closed-source models often come with licensing fees, which can be a significant trouble for bootstrapping startups or agencies with low budgets.
- Transparency Lack. The other disadvantage of closed-source models is that such models may lack transparency regarding their internal architecture, making it challenging for their users to fully understand how decisions are made or to address potential biases in the model



