
A New Era of Large Vision Models (LVMs) after the LLMs epoch: approach, examples, use cases

Table Of Contents:
- Introduction
- What is a large vision model (LVM)?
- LVMs vs. LLMs: What's the Difference?
- What are the examples of large vision models?
- OpenAI’s CLIP
- Meta’s DINOv2
- Google’s VIT
- Landing AI’s LandingLens
- What are large vision models use cases?
- What are large vision models challenges?
- The Future of Large Vision Model (LVM)
- LVM Development Growth
- NLP & LVM Connection
- Cross-Industry Potential
- Сonclusion
Introduction
According to Authority Haker research, about 35% of the whole world's businesses use AI nowadays. It shows significant growth in using AI in all business automation processes. So, we can’t deny that Artificial Intelligence and Machine Learning will touch almost every company in the near future.

Machine Learning and Transformer Models have already become the core part of the generative AI industry. In recent years, LLMs have proven their game-changing usage in developing AI Chatbots and Virtual Assistants. We are moving to a new era - the period of Large Vision Models (LVMs).
So, let’s have a look at how Large Vision Models jumped into the generative AI market, how they work, and where they can be particularly used in real business life. In this article, we will try to show you the origin of the LVM, its approach, use cases, and different examples.
What is a large vision model (LVM)?
Definition
Large vision model (LVM) is a sophisticated artificial intelligence (AI) system developed to analyze and comprehend visual information, primarily images or videos. LVM can be viewed as the visual counterparts of large language models (LLMs). These models are characterized by their extensive parameter count, often numbering in the millions or even billions, enabling them to grasp intricate visual patterns.
Design
The architecture of large vision models involves leveraging advanced neural network architectures. Initially, Convolutional Neural Networks (CNNs) dominated the field of image processing owing to their adeptness at handling pixel data efficiently and identifying hierarchical features. Recently, transformer models, originally tailored for natural language processing, have been repurposed for a variety of visual tasks, delivering enhanced performance in certain contexts.
Training
In order to train large vision models, an extensive volume of visual data, such as images or videos, is provided alongside pertinent labels or annotations within a progressive sequential modeling framework. Trainers meticulously label expansive image collections to supply the models with context.
OpenAI designers created a perfect schema to see how it works:
For instance, in tasks like image classification, each image is tagged with its corresponding class. The model iteratively refines its parameters to minimize the variance between its predictions and the ground truth labels. This endeavor demands substantial computational resources and a vast, heterogeneous dataset to foster the model's capacity for effective generalization to novel, unseen data.
For example, in the task of image captioning, a natural language description of an image like "A man mowing a lawn on a sunny day" is generated. Likewise, in visual question-answering scenarios, LVMs exhibit adeptness in providing nuanced responses to natural language inquiries regarding images, such as "What color is the lawn mower?"
This is actually how LVM works. Now, let’s move to the difference between Large Language and Large Visual Models.
LVMs vs. LLMs: What's the Difference?
Before talking about LLM LVM difference, let’s briefly remind ourselves how LLMs work and how they connect to NLP.
A large Language Model is a specific type of NLP model that is trained on large amounts of text data using deep learning techniques, particularly models like GPT (Generative Pre-trained Transformer). Such a model is capable of understanding and generating human-like text based on the patterns they learn from the training data.
Basically, LLMs are a key component of NLP systems. They enable computers to understand and generate human-like text, which is essential for a wide range of NLP applications such as AI chatbots, language translation, text summarization, sentiment analysis, and more. LLMs provide the underlying technology for many NLP applications by serving as powerful language models that can handle diverse linguistic tasks with high accuracy.
Let’s have a look at the schema below which shows how LVM and LLM correspond with each other.

So, although LVMs and LLMs stem from a common conceptual background, they diverge significantly in their application and effectiveness. LLMs, in particular, have demonstrated exceptional proficiency in comprehending and generating text through extensive training on vast repositories of internet-based textual data.
This achievement is predicated on a pivotal observation: the resemblance between internet text and proprietary documents is substantial enough to enable LLMs to adeptly adapt and comprehend a broad spectrum of textual content. And that’s why we see now the main LLM LVM difference.
What are the examples of large vision models?
There are at least four huge companies that have already been recognized as top-notch accelerators in LVM examples today:
- OpenAI
- Meta
- LandingAI
So, let’s dive deeper into the LVM examples that these companies developed and support.
OpenAI’s CLIP
CLIP or Contrastive Language-Image Pretraining is a neural network, that undergoes training using diverse sets of images and corresponding text captions. Through this process, it acquires the ability to comprehend and articulate the content depicted in images in a manner consistent with natural language descriptions.

Leveraging this capability, the model can undertake a multitude of vision-related tasks, including zero-shot classification, by interpreting images within the context of natural language. This model can be easily used in many Generative AI startups. Its training dataset comprises 400 million pairs of images and text, enabling it to effectively bridge the gap between computer vision and natural language processing. Consequently, CLIP demonstrates proficiency in tasks such as caption prediction and image summarization, even without explicit training for these specific objectives.
Meta’s DINOv2
DINOv2 is a self-supervised Vision Transformer Model from a family of foundation models producing universal features suitable for image-level visual tasks (image classification, instance retrieval, video understanding) as well as pixel-level visual tasks (depth estimation, semantic segmentation).
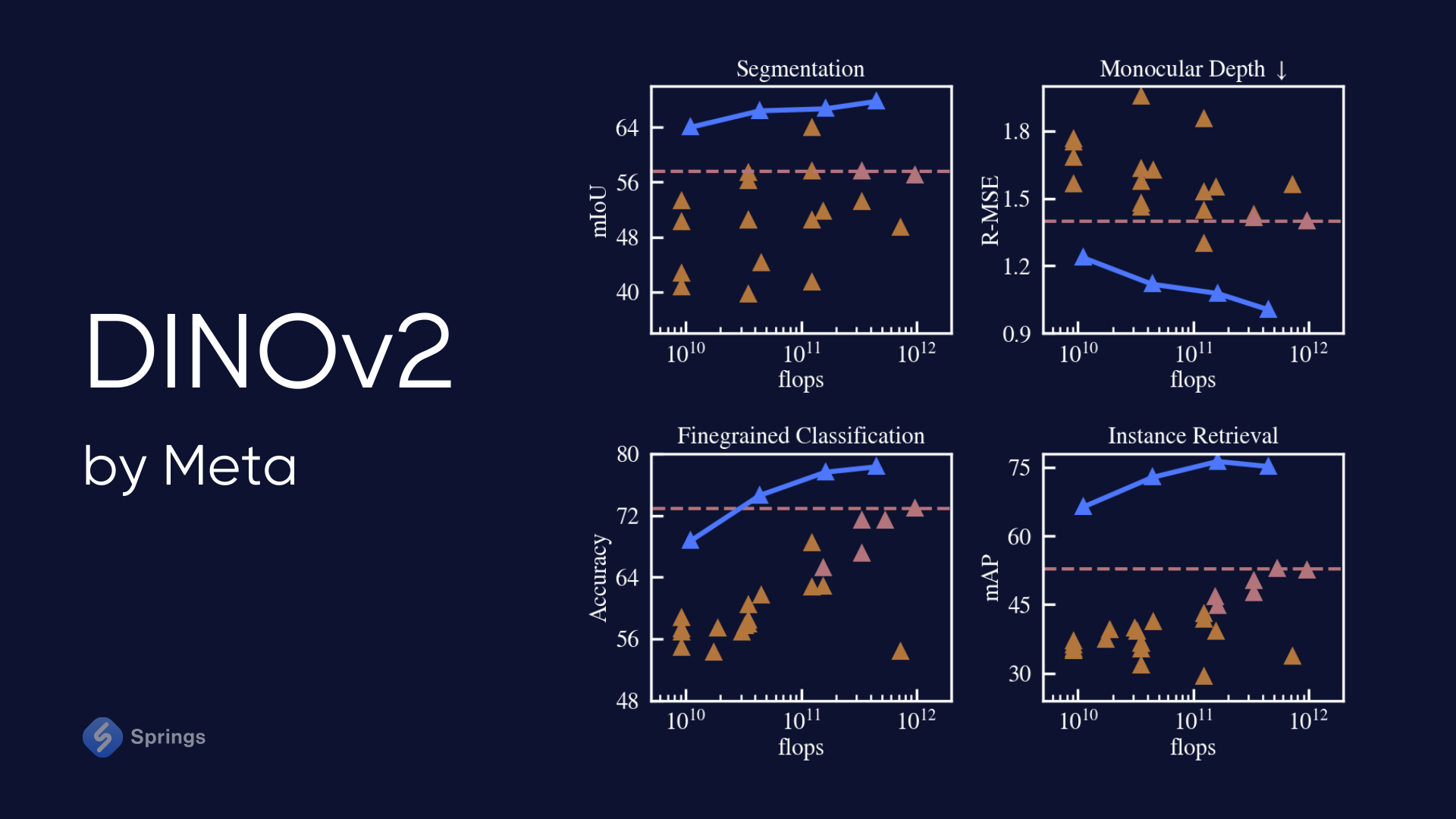
A substantial pretraining dataset comprising 142 million images was meticulously assembled and curated from web-crawled data, ensuring comprehensive coverage across various essential visual domains. This approach extends upon the foundations laid by DINO and iBOT, incorporating several modifications aimed at enhancing both the quality of features and the efficiency of the pretraining process.
Furthermore, the frozen features generated by the models undergo evaluation across a range of visual tasks, including coarse and fine-grained visual classification, as well as video comprehension. These results are meticulously compared against alternative methods employing self-supervised and weakly supervised techniques.
Google’s VIT
Google's Vision Transformer (ViT) completely adopts the transformer model’s architecture, initially employed in natural language processing, for image or even face recognition endeavors. It adopts a methodology akin to how transformers handle sequences of words when processing images, demonstrating efficacy in discerning pertinent features from image data for classification and analytical purposes. Moreover, The Vision Transformer treats an input image as a sequence of patches, akin to a series of word embeddings generated by a natural language processing (NLP) Transformer.
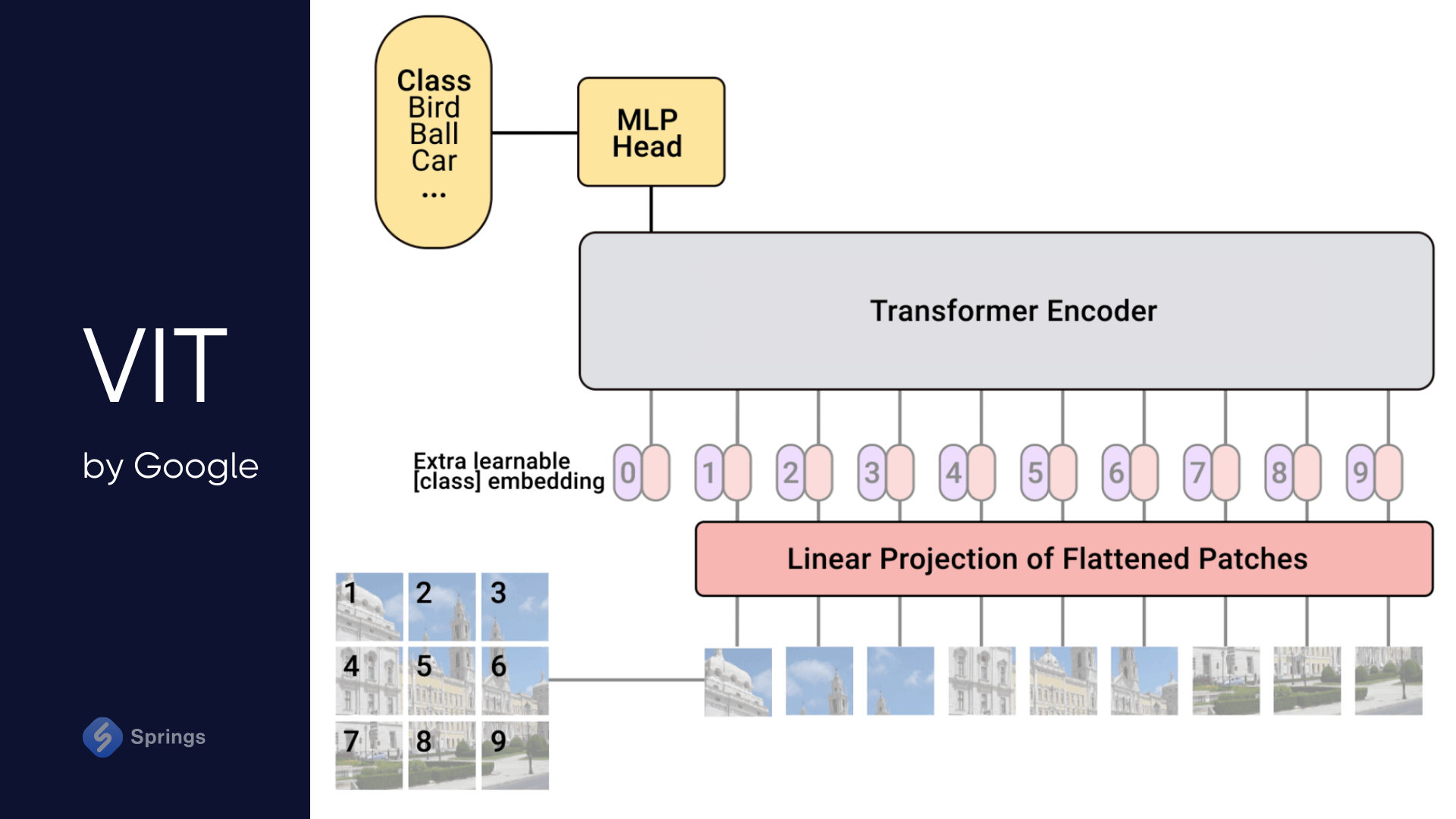
Using the Vision Transformer framework, images are perceived as a sequence of patches. Each patch is flattened into an individual vector, akin to the utilization of word embeddings in transformers for textual data. This approach empowers ViT to autonomously grasp the structural aspects of images and make predictions regarding class labels.
Landing AI’s LandingLens
LandingLens from LandingAI stands as a platform that was created to streamline the creation and development of computer vision models. This platform is one of LVM examples that lets users conceive and evaluate AI projects centered around visual data, catering to a diverse array of industries without necessitating extensive expertise in AI or intricate programming skills.
By standardizing different deep learning solutions, the platform mitigates development duration and facilitates seamless scalability on a global scale. Users retain the flexibility to construct their own deep-learning models and fine-tune inspection accuracy without compromising production efficiency.
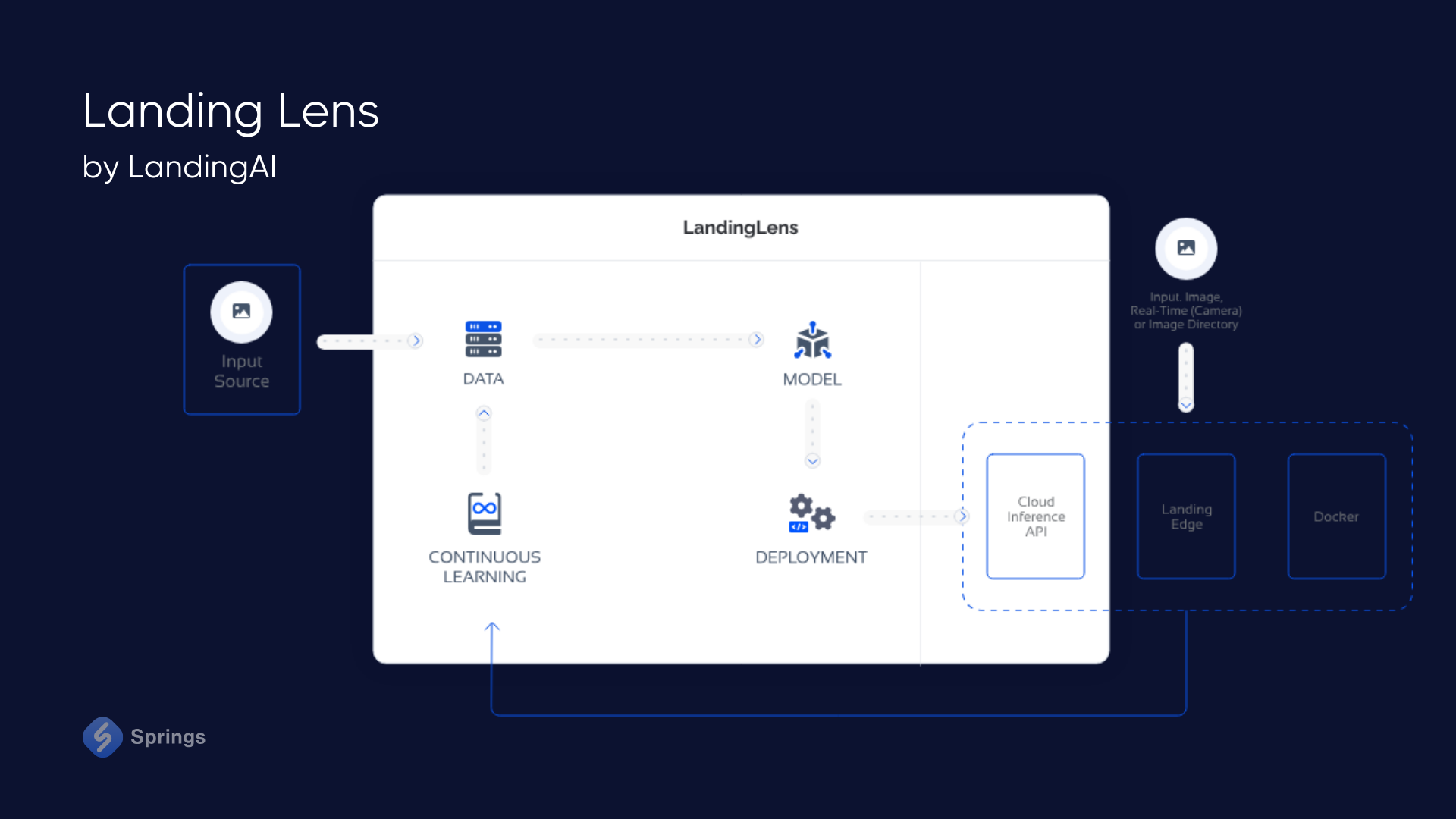
So, in this way, using Landing AI's LVMs, the platform prioritizes a substantial reduction in development timelines, condensing months of work into mere weeks, while simplifying processes such as labeling, training, and model deployment.
Offering an intuitive, step-by-step user interface, LandingLens streamlines the development journey, giving the possibility for AI developers to craft domain-specific LVMs devoid of the need for profound technical expertise.
What are large vision models use cases?
LVM use cases: where we may use large vision models today? What are the ways of integrating the LVMs into different domain ad businesses? Let’s try to find out.
Large Vision Models find applications across various industries, ranging from healthcare and eCommerce to security, retail, entertainment, and environmental monitoring, demonstrating their versatility and significance in modern technological advancements.
Content creation and entertainment:
- Film and video editing: LVMs automate aspects of video editing and post-production.
- Game development: They enhance the creation of realistic environments and characters.
- Photo and video enhancement: These models improve the quality of images and videos.
- Content moderation: LVMs automatically detect and flag inappropriate or harmful visual content.
Healthcare and medical imaging:
- Disease diagnosis: Identifying ailments from medical images like X-rays, MRIs, or CT scans, such as detecting tumors, fractures, or anomalies.
- Pathology: Examining tissue samples in pathology to detect signs of diseases such as cancer.
- Ophthalmology: Aiding in disease diagnosis through analysis of retinal images.
Logistics and transportation:
- Navigation and obstacle avoidance: Assisting autonomous vehicles and drones in maneuvering and evading obstacles by interpreting real-time visual data.
- ML in logistics: Employing AI-powered vision applications to aid robots in sorting, assembling, and quality inspection tasks.
Security and surveillance:
- Facial recognition: Utilized in security systems for identity verification and tracking purposes.
- Activity Monitoring: Analyzing video streams to identify unusual or suspicious behaviors.
eCommerce and Retail:
- Visual search: Enabling customers to search for products using images instead of text in the eCommerce industry.
- Inventory management: Automating inventory monitoring and management through visual recognition technology.
Agriculture:
- Crop monitoring and analysis: Monitoring crop health and growth using drone or satellite imagery.
- Pest detection: Identifying pests and diseases affecting crops.
Environmental monitoring:
- Wildlife tracking: Identifying and tracking wildlife for conservation efforts.
- Land use and land cover analysis: Monitoring changes in land use and vegetation cover over time.
Overall, LVMs can be tailored for edge devices through compression and optimization techniques such as pruning, quantization, or distillation. Pruning eliminates superfluous or redundant parameters, quantization diminishes the number of bits utilized to represent each parameter, while distillation transfers knowledge from larger models to smaller ones.
By employing these methodologies and using modern AI technologies, LVMs streamline their size, memory footprint, and latency, all the while maintaining performance integrity. This adaptability renders them well-suited and scalable across various applications and hardware environments.
What are large vision models challenges?
Despite the considerable potential, Large Vision Models (LVMs) face many challenges that must be effectively addressed to facilitate widespread adoption and ethical usage. One pivotal concern revolves around data bias, as models trained on biased datasets may meet societal biases. Addressing this challenge necessitates the establishment of measures to ensure the diversity and representativeness of training data.
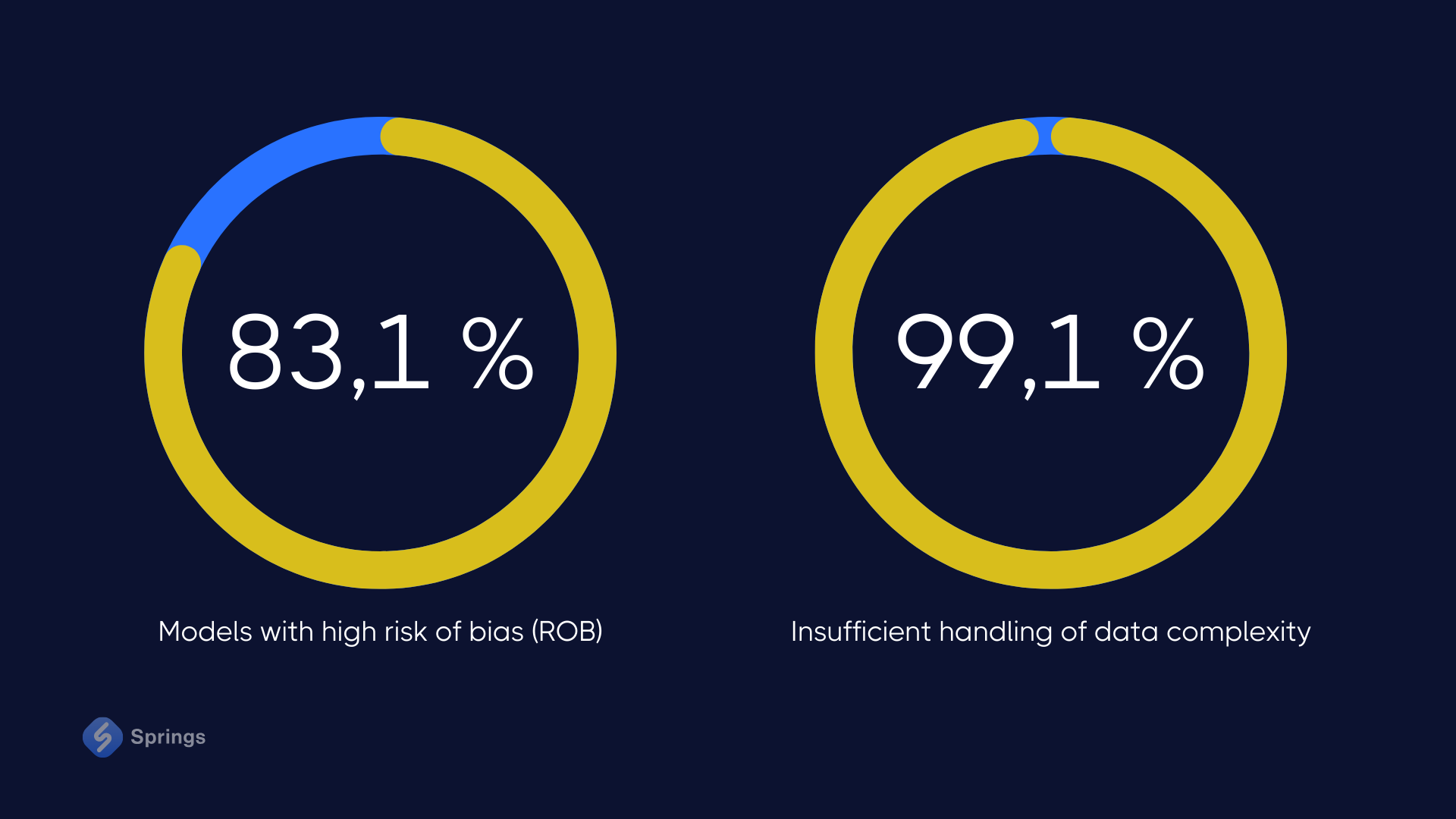
According to Diagnostic imaging research, out of 555 AI models, the researchers found that 83.1 percent (461 models) had a high risk of bias (ROB). The meta-analysis authors also noted inadequate sample sizes in 71.7 percent (398 models) and insufficient handling of data complexity in 99.1 percent (550 models) of the AL models.
Another obstacle stems from the interpretability of LVMs, owing to the intricate nature of deep neural networks. Instilling trust in these models entails the development of methodologies to elucidate and comprehend their decision-making processes effectively.
Furthermore, the substantial computational resources required for both training and deployment pose a potential barrier for generative AI startups and researchers. As LVMs continue to burgeon in size and complexity, ensuring accessibility becomes an imperative consideration.
Finally, privacy concerns loom large, particularly in the context of LVMs employed in surveillance applications. Striking a delicate balance between harnessing the advantages of this technology and upholding individual privacy rights is paramount for ethical and responsible deployment.
The Future of Large Vision Model (LVM)
Looking into the future, the path of large vision models in AI/ML development holds immense promise for revolutionary advancements, not only shaping the technical landscape but also transforming the operational dynamics of industries.
LVM Development Growth
Continuous research and development efforts in the realm of large vision models are poised to push the boundaries of what is achievable. Engineers are actively exploring innovative architectures, optimization techniques, and training methodologies to enhance the efficiency and performance of these models. Persistent endeavors to address challenges such as model interpretability, reducing computational demands, and developing energy-efficient solutions are expected to drive the development of large vision models.
NLP & LVM Connection
The convergence of large vision models with other AI technologies promises to create synergies that amplify the overall capabilities of artificial intelligence. Collaborations between large vision models and natural language processing (NLP) models could lead to more holistic AI systems capable of comprehending and generating both visual and textual information. Moreover, the fusion of large vision models with reinforcement learning techniques may facilitate advanced decision-making in dynamic and complex environments.
Cross-Industry Potential
The potential of large vision models across various industries is profound. In healthcare, these models may revolutionize diagnostics, drug discovery, and personalized medicine, augmenting the capabilities of medical professionals. In manufacturing, large vision models could optimize quality control processes, contributing to enhanced efficiency and reduced defects.
Retail stands to benefit from advanced recommendation systems and cashier-less checkout solutions facilitated by these models. Moreover, the integration of large vision models in autonomous vehicles could drive the development of safer and more dependable transportation systems.
The cross-pollination of ideas and technologies from ongoing research is poised to yield solutions that are not only more potent but also more accessible, driving the democratization of AI capabilities across industries, like education, logistics, or automotive. As large vision models continue to evolve, their seamless integration with other AI technologies and their positive impact on diverse sectors herald a future where AI becomes an indispensable component of daily life, enhancing tasks with intelligence, efficiency, and tailored precision.
Conclusion
The companies need to prepare for a future full of AI technologies. LLMs, LVMs, and other AI models have become indispensable entities in the technological realm. As we embrace ongoing research, anticipate interdisciplinary collaborations, and foresee their transformative impact on various industries, it becomes clear that large vision models signify more than just a tool.
These AI models embody a paradigm shift in our approach to and utilization of artificial intelligence. Today, many firms seeking to harness the potential of large vision models require a strategic partner well-versed in this rapidly evolving field. And here is the place where we may help.
Springs is an international team of experienced AI&ML engineers that can help you with AI solution development and ensure responsible AI deployment. Springs is dedicated to leading the charge in this technological evolution. Through a blend of innovative solutions and a client-centric ethos, Springs’ team empowers businesses not only to adopt large vision models seamlessly but also to stay ahead in the dynamic landscape of artificial intelligence.



